AI Crawler (KI-Crawler): Definition, Bot-Übersicht und Steuerung
Automatisiertes Programm, mit dem KI-Anbieter wie OpenAI, Anthropic oder Perplexity Webinhalte für KI-Training und Live-Antworten in ChatGPT, Claude und Co. abrufen.

KI-Anbieter wie OpenAI, Anthropic und Google haben seit August 2023 dokumentierte Crawler im Web aktiv, die Inhalte entweder für das Modell-Training oder für Live-Antworten in ChatGPT, Claude oder Gemini abrufen. Während der allgemeine Crawler-Begriff (siehe Crawler) auch Suchmaschinen-Bots wie Googlebot meint, fokussiert dieser Eintrag ausschließlich die spezifische Klasse der AI Crawler: ihre Bots, ihre Steuerung und die rechtliche Lage.
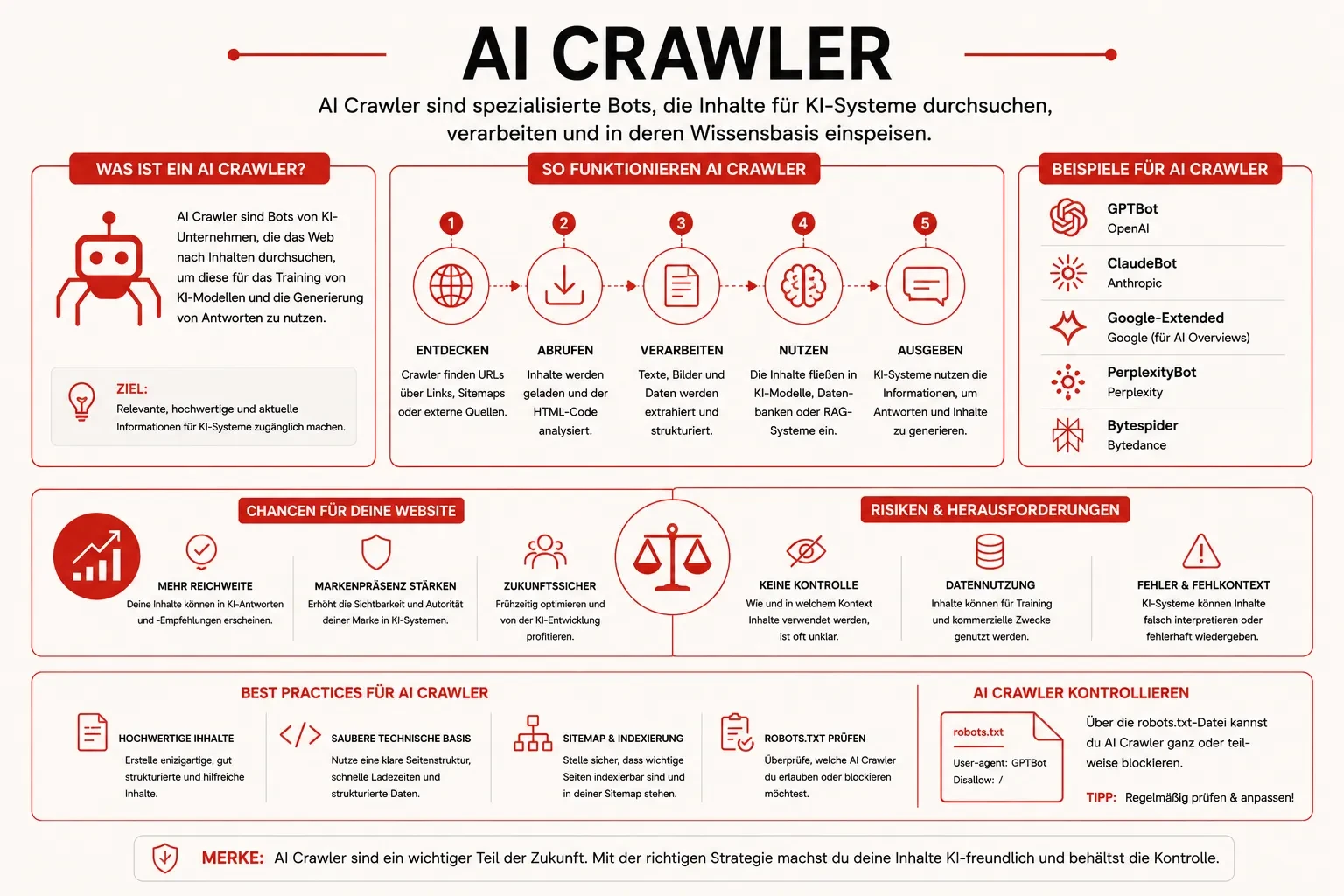
Was ist ein AI Crawler?
Ein AI Crawler ist ein automatisiertes Programm, mit dem Anbieter generativer KI Webinhalte abrufen. Sein Auftrag ist entweder, Sprachmodelle zu trainieren, oder eine konkrete Nutzerfrage in einem Chat-Interface live zu beantworten. Damit unterscheidet er sich grundsätzlich vom klassischen Suchmaschinen-Crawler, dessen Ziel die Aufnahme einer URL in einen Suchindex ist.
Zu den dokumentierten AI Crawlern zählen unter anderem GPTBot, ChatGPT-User und OAI-SearchBot von OpenAI, ClaudeBot und Claude-User von Anthropic, PerplexityBot und Perplexity-User, Google-Extended sowie Bytespider von ByteDance.
Wie funktioniert ein AI Crawler?
Ein AI Crawler arbeitet im Kern wie jeder andere Webcrawler: Er folgt Hyperlinks, lädt HTML-Dokumente herunter, extrahiert Text und übergibt das Ergebnis an ein nachgelagertes System. Der Unterschied liegt in zwei Punkten: im Auftrag und in der Frequenz.
Auftrag. Ein Trainings-Crawler wie GPTBot (OpenAI) oder ClaudeBot (Anthropic) sammelt Inhalte für die nächste Generation eines Sprachmodells. Diese Daten fließen in das Pretraining oder das Finetuning ein und sind anschließend Teil des Modellgewichts, nicht mehr identifizierbar pro Quelle.
Ein Retrieval-Crawler wie ChatGPT-User, Claude-User oder PerplexityBot dagegen ruft Inhalte erst dann ab, wenn ein konkreter Nutzer eine konkrete Frage stellt, deren Antwort eine externe Quelle verlangt. Die abgerufene Seite wird im Antwort-Generator referenziert, oft mit Zitations-Link.
Frequenz. Während Googlebot pro Tag dieselben Seiten mehrfach besuchen kann, schwankt die AI-Crawler-Aktivität stärker. Trainings-Crawls können tagelang laufen, Retrieval-Anfragen dauern Sekundenbruchteile.
Werden Ihre technischen Datenblätter überhaupt von AI Crawlern erreicht, oder verstecken sich die Spec-Sheets hinter einem Login? Diese Frage entscheidet, ob ein Maschinenbauer in einer ChatGPT-Antwort zur Steuerungstechnik-Auswahl auftaucht oder unsichtbar bleibt.
Welche Arten von AI Crawlern gibt es?
AI Crawler lassen sich nach ihrem Auftrag in drei Klassen unterteilen. Genau diese Trennung entscheidet darüber, welche Bots Sie blockieren sollten und welche nicht.
Trainings-Crawler sammeln Daten für die nächste Modell-Generation. Wer sie blockiert, schließt aus, dass die eigenen Inhalte Teil des Modellgewichts werden. Retrieval-Crawler rufen Inhalte live ab, wenn ein Nutzer im Chat-Interface eine Frage stellt. Wer sie blockiert, verschwindet aus den AI-Antworten und damit aus einem zunehmend wichtigen Sichtbarkeitskanal. Search-Index-Crawler wie OAI-SearchBot bauen einen separaten Suchindex für AI-Suchprodukte (z.B. ChatGPT-Search) auf.
| Bot | Betreiber | Klasse | User-Agent-String | Default-Empfehlung |
|---|---|---|---|---|
| GPTBot | OpenAI | Training | GPTBot | B2B mit Premium-Content: blockieren |
| ChatGPT-User | OpenAI | Retrieval | ChatGPT-User | Erlauben (sonst keine ChatGPT-Zitationen) |
| OAI-SearchBot | OpenAI | Search-Index | OAI-SearchBot | Erlauben (sonst nicht in ChatGPT-Search) |
| ClaudeBot | Anthropic | Training | ClaudeBot | Blockieren wenn Training unerwünscht |
| Claude-User | Anthropic | Retrieval | Claude-User | Erlauben (sonst keine Claude-Zitationen) |
| PerplexityBot | Perplexity | Training/Retrieval-Mix | PerplexityBot | Erlauben (Perplexity zitiert quellenstark) |
| Perplexity-User | Perplexity | Retrieval | Perplexity-User | Erlauben |
| Google-Extended | Training (Gemini) | Google-Extended | Blockieren wenn Training unerwünscht; Googlebot bleibt davon unberührt | |
| Bytespider | ByteDance | Training | Bytespider | In DACH-B2B selten relevant, meist blockieren |
| Applebot-Extended | Apple | Training (Apple Intelligence) | Applebot-Extended | Default blockieren |
Konkret: Ein Werkzeugmaschinenbauer, der sein Whitepaper-Archiv hinter Premium-Content schützen will, blockiert GPTBot, ClaudeBot und Google-Extended. Gleichzeitig muss er explizit zulassen, dass ChatGPT-User und Claude-User die öffentlichen Produktseiten weiter live abrufen dürfen. Beides zusammen ergibt erst die richtige Konfiguration.
AI Crawler und SEO: Warum wichtig?
AI Crawler entscheiden mit, ob Ihre Inhalte in ChatGPT-, Claude- oder Perplexity-Antworten als Quelle auftauchen, ob Ihre Marke beim Modell-Training Erwähnung findet, und welche rechtlichen Pflichten ab August 2026 mit dem EU AI Act greifen.
- Sichtbarkeit in AI-Antworten: Retrieval-Crawler wie ChatGPT-User und Claude-User sind das AI-Pendant zum Googlebot. Wer sie aussperrt, taucht in keiner Live-Antwort auf, auch nicht, wenn die eigene Marke in der Frage genannt wird.
- Schutz von Premium-Content: Trainings-Crawler nehmen Inhalte dauerhaft ins Modell auf. Wer Studien, Whitepaper oder differenzierende Daten produziert, hat ein legitimes Interesse, diese Inhalte aus dem Training zurückzuhalten, gerade dann, wenn die Inhalte selbst Teil des Geschäftsmodells sind.
- Rechtliche Sorgfalt: § 44b UrhG erlaubt Text- und Data-Mining grundsätzlich, AUSSER der Rechteinhaber spricht einen maschinenlesbaren Vorbehalt aus. Wer den Vorbehalt nicht ausspricht, hat das Crawling implizit erlaubt. Diese Tatsache ist in vielen Mittelstands-Marketingteams noch nicht angekommen.
- Brand-Mentions im Modellgewicht: Wenn die eigene Marke im Modell trainiert wurde, taucht sie in Antworten häufiger auf, auch ohne Live-Retrieval. Diese Wirkung lässt sich nicht messen, aber begünstigt langfristige Markenpräsenz.
Ein Zulieferer für Industrieelektrik mit 4.000 Produktvarianten muss diese Bilanz für jede Produkt-Sub-Kategorie ziehen: Welche Inhalte gehören in das Modell-Training (= dauerhafte Brand-Präsenz, kein Klick), welche in die Retrieval-Antwort (= Klick mit Quellen-Link), welche bleiben hinter dem Login?
Die meisten Agenturen setzen stattdessen pauschal eine User-agent: * Disallow: /-Regel und nennen das „AI-Schutz“. Sie übersehen, dass sie damit auch die Retrieval-Bots aussperren, die für Sichtbarkeit in ChatGPT-Search verantwortlich sind.
AI Crawler in der Praxis: Steuerung und Einflussfaktoren
Die Steuerung läuft auf drei Ebenen: deklarativ über robots.txt, technisch über IP-Range-Verifikation und durchsetzend über eine Web Application Firewall. Jede Ebene allein hat blinde Flecken; erst die Kombination ergibt einen verlässlichen Block.
robots.txt: User-Agent-basierter Block
Der erste Schritt ist die robots.txt-Datei im Root-Verzeichnis. Das etablierte Protokoll ist seit September 2022 als RFC 9309 (Robots Exclusion Protocol, IETF Proposed Standard) dokumentiert. Disziplinierte Crawler halten sich daran, und dazu gehören die großen AI-Anbieter ausdrücklich.
# Trainings-Crawler blockieren
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
# Retrieval-Crawler erlauben (Default)
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-User
Allow: /
# Catchall: alle anderen erlauben
User-agent: *
Allow: /Wie blockiere ich AI Crawler?
Ein vollständiger Block braucht drei Schritte: erstens die deklarative Sperre in der robots.txt, zweitens eine technische Verifikation über die offiziellen IP-Bereiche der Anbieter, und drittens eine WAF-Regel, die alles abfängt, was sich nicht ausweisen kann. Wer nur einen der drei Schritte umsetzt, hat einen löchrigen Block und im Zweifelsfall keinen rechtssicheren Vorbehalt nach § 44b UrhG.
IP-Range-Verifikation als Pflicht-Schritt
User-Agent-Strings lassen sich frei setzen, jeder beliebige Bot kann sich als „GPTBot“ ausgeben. Die einzige verlässliche Identifizierung läuft über den Reverse-DNS-Check der anfragenden IP gegen die offiziellen Listen der Anbieter. OpenAI veröffentlicht die GPTBot- und ChatGPT-User-IP-Bereiche, Anthropic dokumentiert die ClaudeBot-Ranges in seiner Hilfe.
# Reverse-DNS-Check für eine Crawler-IP
host 23.45.67.89
# Ergebnis prüfen: zeigt die Domain auf openai.com, anthropic.com etc.?Ohne diesen Schritt ist jede Disallow-Regel umgehbar; ein Vorbehalt nach § 44b UrhG ist nur dann „maschinenlesbar wirksam“, wenn er auch real durchgesetzt werden kann.
Cloudflare-WAF als Durchsetzungs-Schicht
Cloudflare bietet seit 2024 die Funktion „AI Crawl Control“ (vormals „AI Audit“), mit der sich AI-Bots auf Edge-Ebene erkennen und blockieren lassen, auch dann, wenn sie sich als Browser ausgeben. Vergleichbar funktionieren Fastly-Regeln und AWS WAF-Policies. Diese Schicht greift nach robots.txt und IP-Verifikation und fängt alles ab, was sich nicht ausweisen kann.
Live-Verifikation via Server-Logs
Was tatsächlich passiert, sehen Sie nur im Server-Log. Ein einfacher Filter auf User-Agent-Strings (grep-Pattern für GPTBot|ClaudeBot|PerplexityBot|Google-Extended) zeigt, wie oft welcher Bot welche URLs abruft. In der Search Console erscheinen AI-Crawler nicht; die Crawl-Statistiken dort beziehen sich ausschließlich auf Googlebot. Wer wissen will, ob ChatGPT-User die eigenen Produktseiten überhaupt findet, prüft die Logs.
Sonderfall: Ist Web-Crawling legal?
Web-Crawling ist in Deutschland grundsätzlich rechtmäßig. Entscheidend ist, ob der Rechteinhaber einen maschinenlesbaren Vorbehalt ausgesprochen hat. § 44b UrhG (in Kraft seit 7. Juni 2021) erlaubt Text- und Data-Mining für jeden, AUSSER der Berechtigte hat den Vorbehalt nach Absatz 3 erklärt. Der Vorbehalt muss „maschinenlesbar“ sein; etabliert sind dafür robots.txt und der Standard-Vorschlag TDMRep der W3C-Community.
Konkret heißt das für den Mittelstand: Wer keinen Vorbehalt aussprechen lässt, hat das Crawling und damit auch das Training auf den eigenen Inhalten implizit erlaubt. Das ist ein häufiger Irrtum in Marketingteams, die annehmen, das Urheberrecht „schütze automatisch“.
Ergänzend wirkt der EU AI Act: Die Pflichten für „General-Purpose AI Models“ (GPAI) nach Artikel 53 gelten seit 2. August 2025; die Durchsetzung durch das EU AI Office beginnt am 2. August 2026. Anbieter müssen seither eine ausreichend detaillierte Zusammenfassung ihrer Trainingsinhalte vorlegen.
Für Webseiten-Betreiber bedeutet das: Wer einen § 44b-Vorbehalt ausspricht, kann sich künftig auf diese Transparenzpflicht berufen, um Verletzungen zu identifizieren.
DSGVO-Aspekte sind im B2B-Bereich meist nachrangig, weil die meisten Crawler keine personenbezogenen Daten verarbeiten. Relevant wird die DSGVO erst, wenn z.B. Mitarbeiter-Profile, Kunden-Stimmen oder Kommentare gecrawlt werden. In diesen Fällen ist die Rechtsgrundlage nach Art. 6 DSGVO zu prüfen.
Fazit & Takeaways
- Trainings vs. Retrieval pauschal blockieren ist der häufigste Fehler. Trennen Sie GPTBot, ClaudeBot und Google-Extended (Training) von ChatGPT-User, Claude-User und Perplexity-User (Retrieval), sonst verlieren Sie Zitationen.
- Verlässlich blockieren heißt drei Schritte: robots.txt, IP-Range-Verifikation, WAF-Regel. Wer nur den ersten Schritt geht, vertraut auf Goodwill, der bei weniger seriösen Crawlern fehlt.
- § 44b UrhG verlangt einen aktiven Vorbehalt. Ohne maschinenlesbare Erklärung gilt Crawling als erlaubt; die meisten Mittelstands-Sites haben den Vorbehalt aktuell nicht ausgesprochen.
Verwandte Begriffe
- Crawler: Oberbegriff aller automatisierten Web-Abruf-Programme, von Googlebot über Tool-Crawler bis zu AI Crawlern.
- Crawling: Der Prozess des automatisierten Webseiten-Abrufs, unabhängig vom Crawler-Typ.
- Indexierung: Schritt nach dem Crawling, also die Aufnahme einer URL in einen Suchindex (klassisch oder AI-Search-Index).
- GEO (Generative Engine Optimization): Disziplin, die Inhalte gezielt für AI-Antwortmaschinen optimiert; direkter Anschluss an die Retrieval-Crawler-Steuerung.
Autor: Daniel Neubauer, Geschäftsführer RED RAM MEDIA. Über 16 Jahre Agentur- und SEO-Erfahrung, seit 2010 Agenturinhaber, Entwickler des VISIBL-Frameworks für technisches B2B-SEO.
Häufige Fragen (FAQ)
Was ist ein AI Crawler?
Ein AI Crawler ist ein automatisiertes Programm, das Webinhalte für KI-Anbieter wie OpenAI, Anthropic, Google oder Perplexity abruft. Er unterscheidet sich vom klassischen Suchmaschinen-Crawler in seinem Zweck: nicht Indexierung für eine SERP, sondern entweder Training eines Sprachmodells oder Live-Antwort auf eine Nutzerfrage. Die wichtigsten Vertreter sind GPTBot, ClaudeBot, PerplexityBot und Google-Extended.
Was ist der Unterschied zwischen GPTBot und ChatGPT-User?
GPTBot ruft Inhalte für das Training künftiger OpenAI-Modelle ab. ChatGPT-User ruft Inhalte live ab, wenn ein Nutzer in ChatGPT eine Frage stellt, deren Antwort eine externe Seite verlangt. Wer GPTBot blockiert, schließt Trainingsdaten aus. Wer ChatGPT-User blockiert, fliegt aus den Live-Antworten der ChatGPT-Suche raus. Das sind zwei sehr unterschiedliche wirtschaftliche Konsequenzen.
Reicht robots.txt aus, um AI Crawler zu sperren?
robots.txt ist der erste Schritt, aber nicht ausreichend. Die Datei ist freiwillig nach RFC 9309 — disziplinierte Crawler wie GPTBot oder ClaudeBot halten sich daran, weniger seriöse Crawler ignorieren sie. Außerdem lässt sich der User-Agent frei setzen. Ein verlässlicher Block kombiniert robots.txt mit IP-Range-Verifikation und einer WAF-Regel.
Ist Web-Crawling in Deutschland legal?
§ 44b UrhG erlaubt Text- und Data-Mining grundsätzlich. Wer es untersagen will, muss einen maschinenlesbaren Vorbehalt aussprechen — typisch via robots.txt oder TDMRep. Ohne Vorbehalt gilt das Crawling als rechtmäßig. Zusätzlich verlangt der EU AI Act seit August 2025 von KI-Anbietern Transparenz über ihre Trainingsquellen, die Durchsetzung beginnt am 2. August 2026.
Was ist .well-known/ai.txt?
ai.txt ist ein Vorschlag aus der Spawning AI-Initiative, der gezielt AI-Crawlern Anweisungen geben soll — separat von robots.txt. Stand 2026 ist der Standard noch nicht offiziell beim IETF verabschiedet und wird von den großen Anbietern nicht verbindlich befolgt. Wer Inhalte rechtssicher schützen will, setzt zuerst auf robots.txt-Blöcke und TDMRep.
Welche IP-Ranges nutzen die AI Crawler?
OpenAI veröffentlicht seine GPTBot- und ChatGPT-User-IP-Listen unter platform.openai.com/docs/bots, Anthropic dokumentiert ClaudeBot in der Anthropic-Hilfe. Wer einen Crawler verifizieren will, prüft den Reverse-DNS der Anfrage-IP gegen die offiziellen Listen — User-Agent-Strings allein sind nicht vertrauenswürdig.
Theorie verstanden? So sieht die Praxis aus:
Weitere Begriffe aus dem Lexikon
Core Web Vitals
Core Web Vitals sind drei Google-Metriken für Ladezeit, Interaktivität und Layout-Stabilität. Seit Juni 2021 fließen sie als Ranking-Faktor in die Suche ein und entscheiden bei B2B-Sites über die Sichtbarkeit.
Crawler
Ein Crawler ist das Programm, mit dem Suchmaschinen, Tools und KI-Anbieter das Web durchsuchen. Bei B2B-Relaunches entscheidet sein Verhalten, ob mehrere tausend Produkt-URLs überhaupt im Index landen.
HTTP-Statuscode
Ein HTTP-Statuscode entscheidet, wie Crawler und Browser auf eine URL reagieren. Bei B2B-Relaunches mit mehreren tausend Produkt-URLs bestimmt er, ob bestehende Sichtbarkeit konsolidiert oder verloren wird.
Von der Definition zur konkreten Umsetzung.
Sie kennen jetzt das Konzept. Die Frage ist: Wie wird daraus ein messbarer Hebel für Ihr B2B-Marketing? In 30 Minuten analysieren wir, ob und wie dieser Ansatz zu Ihren Zielen passt.
30 Minuten · Datenbasiert · Klartext